
Ai-generated voices such as Siri and Alexa have become an integral part of twenty-first century society – research into making these voices more personal and expressive is moving fast
Computer scientists and electrical engineers from the University of California San Diego have found a way to alter and improve a wide range of AI technology, by allowing them to mimic the ways in which emotion is conveyed through speech.
Personal assistants for smartphones, cars and homes along with the voice-overs in animated movies and translation of speech in multiple languages are just some of the ways we interact with AI-generated voices on a regular basis. By allowing AI speech to sound more natural and realistic, computer scientists are opening doors for a wide range of technological and AI advancements.
The ability to convey emotion?
“We wanted to look at the challenge of not just synthesising speech but of adding expressive meaning to that speech,” said one of the lead authors, PhD student Shehzeen Hussain.
The ability to convey emotion through speech is something we take for granted on a daily basis, however this programme has the capability to help create personalised speech interfaces for those who have lost the ability to speak and therefore change lives.
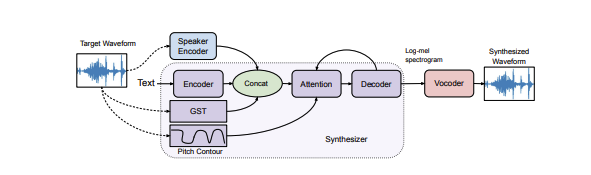
Generating speech has been possible for several years, however creating expressive and relatable speech from an AI source has yet to be achieved anywhere else. The team at UC San Diego were able to flag the pitch and rhythm of the speech in training samples as examples of emotion.
“We demonstrate that our proposed model can make a new voice express, emote, sing or copy the style of a given reference speech,” according to the team. This new cloning system is capable of generating expressive speech with little amounts of training, even for voices it had never come in contact with.
So, how does this work?
This system has the ability to learn speech directly from text, by reconstructing a speech sample from a target speaker and transferring the pitch and rhythm of speech from a different expressive speaker into cloned speech for the target speaker. And although currently the programme is biased towards English and struggles to learn from strong accents the technology can only improve from here.
The ability for this technology to be used in negative ways and have harmful impacts has not been overlooked. The technology to create more expressive and realistic deep fake videos and audio through expressive AI speech is a dangerous tool to wield and that is why the team at UC San Diego have planned to released their code with a watermark that will identify the speech created by their method as cloned.
To listen to some audio examples created by the AI programme click here.








