
Pseudonymisation is a safer approach to prepare your data for analytics, argues Rob Fotheringham, Managing Director from Fotheringham Associates
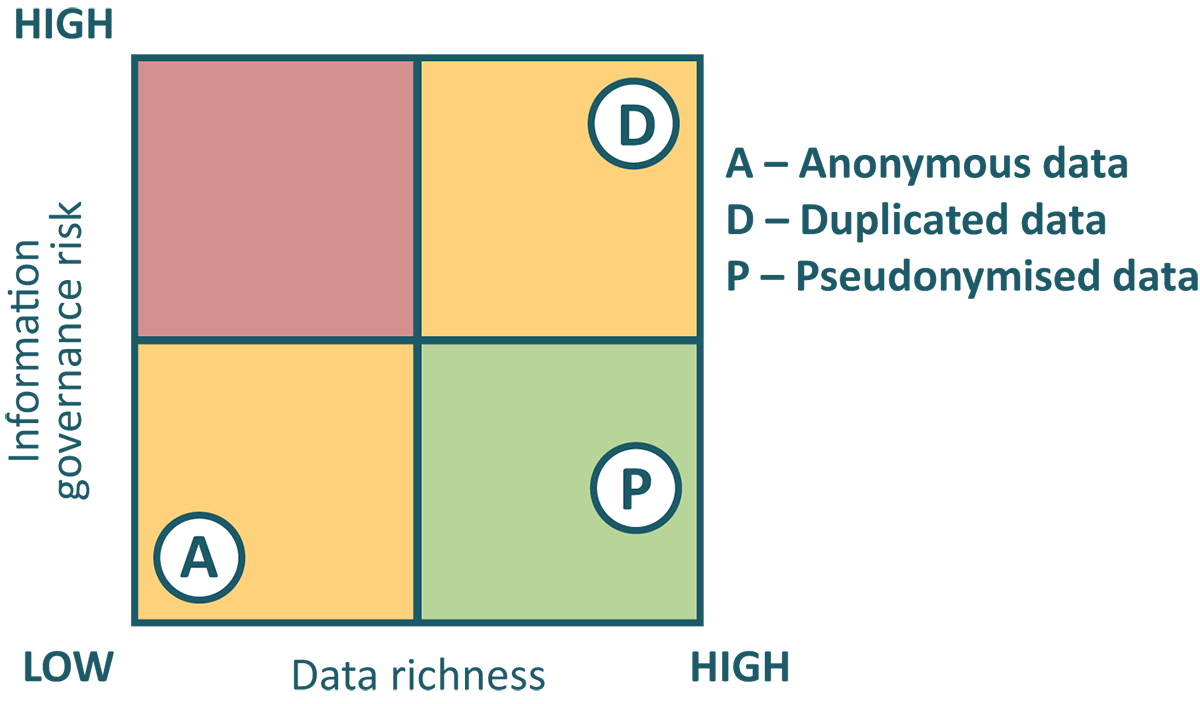
As an organisation, you are sitting on a wealth of operational data that is growing by the day, and you desperately want to use it to conduct research on trends and client behaviour. However, you know that duplicating all the data to provide an analytics database will increase the risk of something going wrong. In fact, it will more than double the risk as data stores used for reporting are typically less well monitored and controlled than operational data used by front line staff. If something does go wrong, it could result in a breach, embarrassing notifications to clients, a report to the Information Commissioners Office and possibly a huge fine.
Do you, therefore, give up or take the risk? Or maybe you decide to anonymise the data to protect yourself from those potential breaches in the reporting data store. Whilst this certainly reduces your information risk, it brings a significant constraint, as you have also rendered it beyond the ability to link it to current live data. The data you anonymise is effectively held in suspended animation on the day that you change it, with no further transactions, behaviour or additions able to be linked to the records. Any new transactions or data changes added to the dataset will create new anonymous data, possibly skewing the numbers and blurring the information landscape to the point at which you cannot draw any accurate insights. Is this really what you want to achieve?
Pseudonymisation – A third option?
You want to aim to build up a rich repository of data for research whilst the operational records are still very much active, the stage at which the data will have the most value to your analytics. To achieve this, you need to adopt a different approach. Pseudonymisation is a technique that uses a key from your current live dataset and transforms it to be unintelligible allowing you to work on the data for research without fear of accidentally publishing personal data or without people having access to personal information that they shouldn’t. However, unlike anonymisation, which uses a random value as the key to the records, the pseudonymised key is a link to the operational system and data can continue to be added to the dataset.
There are a number of ways of achieving pseudonymisation. At Fotheringham Associates, we have designed an approach for a large programme operated by a children’s charity that is straight forward and secure, based upon algorithms provided by the NSA. For this client, we have inserted pseudonymisation into the build of a data integration platform that enables them to gather data from 20 service providers, including three NHS trusts, the local council, several charities and a collection of community groups.
The approach produces identical pseudo keys even when processed in different locations and by different systems which is how we have enabled the diverse environment to work in this programme. In addition, the pseudonymised information cannot be reverse engineered, increasing the protection. When combined with a matching routine the approach is helping to deliver an environment that captures all service users across the programme, adds engagement data each quarter and will allow research data analysts to trace improvements in outcomes across the in-scope population and seek to understand the contributing factors. The power of your research data is not simply in its volume, real data power lies with the connections between elements.
Weigh up your options
We urge you to consider the approach to creating research data stores carefully, never before have the trade-offs been more important with regulators beginning to flex their new muscle under GDPR.
You can make simply duplicating data work with care.
Anonymisation can be the solution for records if they are beyond the point at which the data will be enriched further or you accept the constraints.
Or you can consider pseudonymisation as the path to deliver the best outcome with a good balance of risk and data richness.
It would be remiss not to point out that duplicate data must be included in the application of data subject requests, including SARs (subject access requests), withdrawal of consent and retention rules, the latter two events will need data removed from your duplicate data store as well as the operational one. Whilst this is also true for pseudonymised data, there are a set of processes that can manage such requests.
Therefore, if you are planning the creation of a datastore for analytics or beginning to question the value of the approach and data you have at the moment we urge to seriously consider using a pseudonymization technique which will help protect your organisation, your research data and most importantly, your data subjects.
Please note: This is a commercial profile








