
Francesco Audrino, Professor of Statistics at University of St. Gallen explains financial risk forecasting in the era of big data and underlines the role of investors’ sentiment and attention
Financial markets are a central component of today’s economic systems. They not only facilitate the financing of companies but also provide investment opportunities for individual investors, pension funds and insurance companies. Consequently, models producing accurate future financial scenarios are central ingredients for private and institutional investors, economists, business leaders and policymakers to form realistic opinions about what could come next, how to eventually impact it and to be ready to react to it.
As the 2008 global financial crisis clearly showed, classical models estimated on standard economic and financial data were not fully satisfactory. One of the main problems they suffer is that they are not generally able to incorporate the psychological over- or under-reactions of financial investors to particular events and announcements.
In fact, regardless of the investors’ nature or background, stock market participants make predictions about future developments of stock prices and other investment opportunities that could be influenced by their mood and/or incoherent expectations. Neglecting these collective emotional behaviours could strongly bias the predictions of the models and lead to disastrous consequences such as individual investors’ and companies’ bankruptcies and even system-wide financial crises.
For many years, researchers argued that the formation of an investor’s prediction is purely based on a rational analysis of a company’s revenues, products or more general global trends. Today, however, we know that market participants’ decisions are often influenced by their mood. Investors, for instance, have a tendency to interpret and search for information and news that confirm their beliefs or to align their expectations to those of other investors. The irrational behaviour of individuals has been shown to influence financial markets, especially during a crisis.
The proliferation of the internet and social media platforms has created a huge amount of new data that potentially encloses information about people’s mood (“sentiment”), believes, hopes and fears. For example, after a company publishes its quarterly earnings, we can expect to find related comments and reactions in messages posted on social media platforms.
It is, therefore, a natural step to include such variables into the different financial models to try to take advantage of relevant information about possible emotional investors’ reactions and to improve the accuracy of the obtained financial predictions.
One of the most important financial variables that investors focus on is the level of risk related to a given financial transaction or investment. In particular, volatility, the variation of the price of financial investment in a given time period, is generally interpreted as the risk of the investment. Although volatilities are inherently unobservable, accurate estimates can be obtained by exploiting the information included in the almost continuous flow of recorded financial transactions.
Given the key relevance of volatility in almost all financial applications like portfolio selection or risk management, it is not surprising that many academic researchers during the last few decades focused on introducing accurate ways of understanding and predicting volatility’s time-varying behaviour. The question that remains unanswered is whether the recent availability of data coming from social media and from online users’ web queries could help improving actual predicting tools.
In the recently started SentiVol project, we try to give an answer to this question by analysing the impact of investors’ sentiment and investors’ attention on volatility’s time-varying dynamics.
As illustrated in figure 1, to perform such an analysis there are a couple of practical problems that have to be carefully addressed. First, working with such a huge amount of heterogeneous data (that is, high-frequency transaction data and different sources of web data, such as social media messages, news articles or search engine web queries) is not an easy task from both a computational and a modelling point of view. We overcome these challenges by using high computing power and memory, for example, using cloud computing and applying specific high dimensional modelling techniques coming from computational statistics.
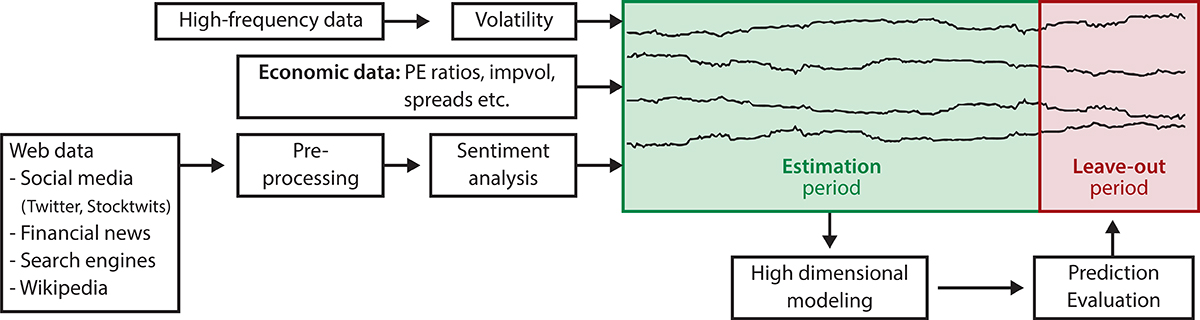
Second, the nature of social media and web queries data makes pre-processing of the data necessary to incorporate the information they contain in a forecasting model. This includes, for instance, the determination of sentiments from textual data. The latter can be efficiently performed using sophisticated machine learning techniques, such as deep learning methods.
Using this big data set, we constructed several variables, such as the daily average sentiment of investors or the total number of daily messages posted on social media platforms about a company or the stock market in general for the period from 2012 to 2016. In a first empirical analysis, we investigated the volatility forecasting improvements achieved by a model exploiting our novel dataset for a selection of U.S. companies and the U.S. stock market index. The results showed that measures of sentiment and investors’ activity improve the predictive accuracy of future volatility, even when controlling for a wide range of economic and financial indicators.
In particular, we found that a high volume of messages posted on the social media platform StockTwits or an increasing amount of web search queries is an early signal of potential stock market volatility peaks. This effect usually lasts one or two days but is particularly strong during periods of market turbulence.
Following our initial findings, our research team currently analyses whether there exist particular channels through which investors’ opinion, mood and activity on the web influence financial prices and volatilities and which type of events and news are mostly related with investors’ emotional reactions. The hope is that the inclusion of sentiment and attention variables in volatility forecasting will lead to a better understanding of the way risks related to financial investments behave. This could be a crucial step to anticipate high volatility phases and potentially reduce the effects of the next crash.
Please note: This is a commercial profile
Francesco Audrino
Professor of Statistics
Tel: +41 71 224 24 31








