
Returning control over our personal data to us through the Blockchain – explored by experts from Swiss Re and IBM Research
- Restoring customer control, trust and transparency over the use of sensitive personal data.
- Easing the burden of data ownership for the insurance industry.
A joint initiative by Swiss Re & the IBM Research Lab
We hate getting insurance. It’s such an impossibly convoluted process. With all the personal data we put out there on the net, why can’t we have a smart app on the mobile that tells us what we need and lets us buy to cover the same way we buy train tickets or books on Amazon?
As an insurance IT professional, I know that dealing with personal sensitive data can be a colossal headache. As an industry, we put a lot into gathering and harmonising such things as policy and claims data – and as soon as we have it, we fret over protecting it from ourselves in accordance with ethical principles and multivariate, fast-evolving legislative frameworks. Tap into other sources like fitness trackers or buying behaviour to drive “Insurance made Simple”? Challenging. Social media? Unthinkable. Or is it?
Trust and transparency
Let’s look at the underlying problem. It all comes down to trust and transparency. Data modellers know that when a model causes inordinate pain it is usually because it does not represent reality quite right. So, where is the flaw in how we deal with personal sensitive data? Well, insurers act as guardians of individuals’ personal sensitive data. And they shouldn’t. The power to decide on who can see my personal data should be with me. Is that possible?
Traditionally, the answer has always been no. There simply wasn’t a way to ask consumers in real time, nor a way to analyse large amounts of highly distributed data. So, we have become accustomed to hoarding that data on our premises, and managing it as best we can. But with the advent of truly distributed technologies, that is changing. If Blockchain can distribute ledgers and even the execution of code snippets that power in-block calculations for smart contracts, why shouldn’t it allow us to distribute decisions on access to distributed data? Even distribute its analytic processing?
Power to the people
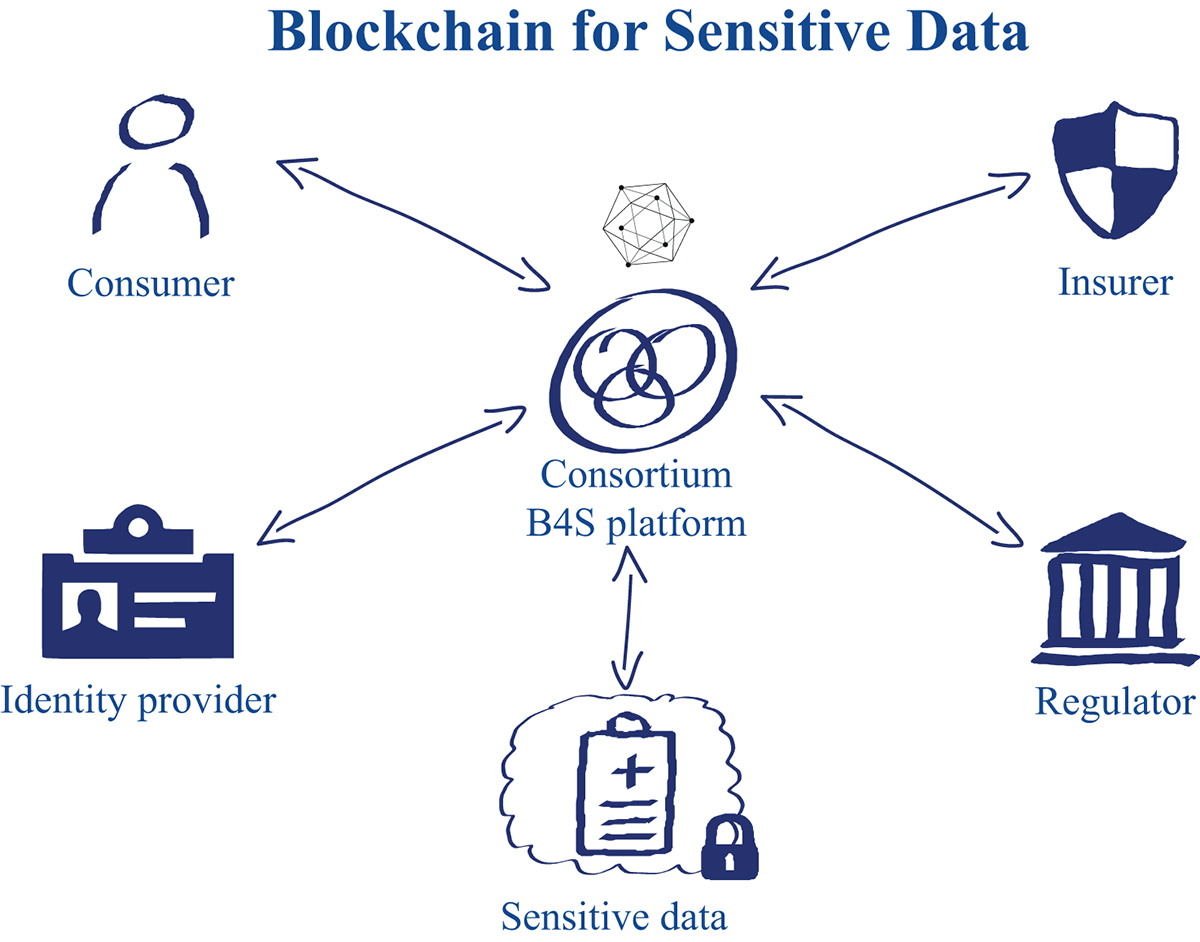
With that idea, a small group of curious minds from Swiss Re’s IT innovation teams and IBM’s Rüschlikon research lab set out to prove or disprove the feasibility of a platform that cleanly separates regulating access to personal sensitive data from storing and analysing that data. A platform that places decision power on access to personal sensitive data in the hands of the individual that data is about, and ensures full transparency on what that data is used for, by whom, when, and under what specific consent. We call it “Blockchain for Sensitive Data”, or “B4S”.
Traditional implementations of this vision are likely to fall short when it comes to their security and privacy guarantees. Indeed, users might not feel comfortable to hand over their sensitive medical data to a single entity: they might (legitimately) feel that they have lost control of where, when and how their data is used, and that they cannot fully exercise their right to opt out or revoke data access. Fortunately, it’s Blockchain to the rescue.
A Blockchain primer
Technically speaking, Blockchain is a distributed operating system that provides an environment to execute so-called smart contracts, and to maintain all the data structures they require (a.k.a. world state).
The novelty with respect to other, more traditional, solutions to the problem is that Blockchain maintains its properties even in presence of buggy/malicious computing nodes.
Let’s use an analogy to understand what this means: we can equate a Blockchain environment to a set of players playing a board game. The board game welcomes more than one player (and so the system is distributed). The players are free to interact with each other (and so they can execute bilateral or multi-lateral transactions).
Each player only needs to look at the board and its pieces to understand the state of the game – who’s winning, who’s losing etc. (and so there is a commonly agreed-upon world state). Crucially, the game may be designed in such a way that the players are forced to behave honestly, or be caught cheating and banned from playing on.
Why blockchain?
Among other things, Blockchain is great at the following scenario: a set of entities would benefit in doing business together but – because of security and trust concerns – one of two things happen: either they don’t do any business, or they do it inefficiently. Blockchain creates the technical foundations so that mistrusting participants can do business together in a way that their actions are limited to what they have previously agreed.
This use case fits perfectly: today medical data isn’t being shared as much as it could. Blockchain creates the technical foundations for this to happen in a way that is acceptable to all.
More specifically:
1) Blockchain helps us create a new virtual entity that is trusted to access medical data on behalf of end consumers; for instance, this entity is trusted to access private healthcare data stored on Dropbox and Fitbit.
Why a virtual entity? Because we have already established that there is no real one (person, people or company) who is trusted by all to centrally handle such data, and so we need one that is created by the Blockchain and whose actions are constrained by the rules of the smart contract.
2) Blockchain enforces this very simple, yet powerful rule: medical data can be accessed if and only if two entities agree: the requester (e.g. an insurer) and the owner (i.e. the consumer); otherwise the request is denied.
Next: Build a community
So, yes, it can be done quite nicely on Blockchain. Next, we need to think about how it can be owned and managed so that end customers and regulators can fully trust it, and we can leverage it to provide value-adding services. We are beginning to reach out to the insurance industry, with the intention of forming a consortium that can build and operate an open industry-wide platform. Later, a foundation or the like could be set up, sharing control with consumer protection experts and regulators.
Under the best of circumstances, this will take a while. By then, distributed analytics SH (sending the algorithm to the data instead of pulling the data to the algorithm), will have taken hold and we will be able to run analyses on whole risk portfolios, with specific consent by individual consumers, without having to own the data.
And what will all that mean for us?
We will be able to have a smart app on our mobiles that walks us through covering our insurance needs in ten minutes every January. And we will know what of our data powers it, that we allowed it, and that the data won’t be (mis)used elsewhere.
And in my insurance job life, I can get on with my work without being afraid of stumbling into non-compliance because of a legal change somewhere that I just had the misfortune to miss. I might even get an easier time with regulators. Because, with full transparency and control for the consumer, they might just find they can relax a bit, too.
Please note: this is a commercial profile
Daniel Thyssen
Business Partner & Digital
Transformation Lead, EMEA
Swiss Re Life & Health
Alessandro Sorniotti
Researcher in security and cryptography
IBM Research – Zurich








